4 Almacenamiento y Curatoria
¿Qué es la Curatoría y como se relaciona con la accesibilidad de los productos de investigación?
El objetivo final de esto es que usted en el futuro, investigadores, estudiantes o público en general, puedan buscar en un repositorio un tema de interés como “Socialización escolar” y con ello acceder fácilmente a distintas bases de datos, transcripciones de entrevistas y experiencias de investigaciones sobre la temática, haciendo más eficiente e informadas las investigaciones. Esto permitirá unas ciencias sociales más rigurosas, más colaborativas y con una preservación capas de acumular evidencia para futuros estudios históricos.
Para poder garantizar un proceso adecuado del almacenamiento de productos de investigación, es necesario alcanzar una buena curatoría, la cual depende de un conjunto de factores. Entre estos factores destacan:
Buenos “datos”. Aunque el concepto se asocia con lo cuantitativo, en este documento nos referimos con dicho termino al conjunto de materiales que son producidos por los proyectos de investigación mediante técnicas de recolección/producción de información que sirven posteriormente para el análisis cualitativo y/o cuantitativo (p. ej. entrevistas, encuestas, transcripciones, recopilaciones). De hecho, los dos repositorios cualitativos más famosos de transcripciones de entrevistas y focus groups (QualiData y QDR) utilizan el termino datos para referirse a esta información producida por investigaciones. Abrir buenos datos al público, significa que estos materiales pueden ser utilizados, comprendidos y trabajados por distintos tipos de investigadores. Esto sin duda implica un esfuerzo por parte de los investigadores a la hora de producir información para asegurar que quede registrada de modo tal que sea accesible y fácil de encontrar para quien la quiera.
Metadatos precisos. Los metadatos son información de los datos que permiten comprender cuál es su contenido y su posible utilidad. Por ejemplo, nombre del material, tipo de material, como fue producida esa información, cual fue la institución e investigadores encargados de su producción, entre otros. Junto con esta descripción de distintos aspectos, se consideran dentro de las ciencias sociales como documentación relevante los manuales de usuario, pautas de entrevistas, bitácoras o cualquier documento que ayudo a la producción de la información o ayuda a ser comprendida.
Infraestructura Digital. Refiere a las páginas web, y las herramientas digitales que puedan ayudar a organizar, localizar y distribuir los datos de las investigaciones. Por ejemplo, es necesario contar con buscadores en los repositorios de materiales de investigación, estos deberían permitir encontrar todas las bases de datos de encuestas y todas las transcripciones de entrevistas que estén asociados a un término de búsqueda como “desigualdad de género” y sus sinónimos. Una herramienta de este tipo de fácil uso, puede ser un gran aporte a las investigaciones de las ciencias sociales.
Organización y practicas abiertas: Para que un servicio de almacenamiento de datos funcione adecuadamente debe existir actitudes, conocimientos y practicas colectivas por parte de los investigadores en torno a cómo y por qué almacenar sus datos abiertamente. Del mismo modo, son necesarios algunas personas dedicadas a la administración de los repositorios en línea y a la formación de los investigadores para adecuase al contexto digital.
En suma, para tener un buen almacenamiento de materiales sociales para investigar, que estén bien clasificados y sean faciles de encontrar, es necesario tener cierta infraestructura digital y procesos de curatoría. Igualmente, estos procesos pueden apoyar la mejora de la calidad de los datos y su difusión a distintos investigadores.
4.0.0.1 Bases de datos y curatoria
Una base de datos es un conjunto de información organizada de modo estructural que permite almacenar distintas capas de información. Las bases de datos no son equivalentes a las matrices (Ver ejemplo de matriz en imagen 1) pues poseen más información además de las variables, lo casos y los valores, como la descripción de las variables, las etiquetas de las categorías o el tipo-clase de información contenida. Incluso las bases de datos pueden contener información sobre el formato en el que están (p ej. SPSS). De hecho, al pasar una base de datos a una simple matriz se pierde información.
En este ejemplo de matriz, podemos ver como la información contenida simplemente posee el nombre de los sujetos (a,b,c), las variables (1,2,3) y los valores (“y”, “x”).
## [,1] [,2] [,3]
## a "1" "2" "3"
## b "3" "2" "1"
## c "2" "3" "1"Ahora veamos la estructura de esta matriz en base al argumento str del sofware R, el cual nos permite visualizar los componentes de un objeto.
## chr [1:3, 1:3] "1" "3" "2" "2" "2" "3" "3" "1" "1"
## - attr(*, "dimnames")=List of 2
## ..$ : chr [1:3] "a" "b" "c"
## ..$ : NULL
## NULLComo se puede ver la estructura de la matriz es relativamente simple. A continuación, se expone la estructura de una base de datos del centro COES, la base ELSOC, esta base fue recortada para solo poseer tres variables como la matriz anterior. Si bien es bastante complejo leer la estructura de la matriz y la base de datos, para este ejercicio basta con darse cuenta de que la base de datos posee una estructura más compleja y mayor información que la matriz.
ELSOC <- read_dta("ELSOC_W01_v2.00_Stata14.dta")
ELSOC_3 <- select(ELSOC, t01, r01_01, c01)
print(str(ELSOC_3))## tibble [2,983 x 3] (S3: tbl_df/tbl/data.frame)
## $ t01 : dbl+lbl [1:2983] 1, 3, 3, 3, 2, 2, 3, 3, 3, 2, 3, 2, 3, 3, 4, 3, 2, 2,...
## ..@ label : chr "Cuanto confia usted en sus vecinos"
## ..@ format.stata: chr "%12.0g"
## ..@ labels : Named num [1:7] -999 -888 1 2 3 4 5
## .. ..- attr(*, "names")= chr [1:7] "No Responde (no leer)" "No Sabe (no leer)" "Muy poco" "Poco" ...
## $ r01_01: dbl+lbl [1:2983] 1, 1, 1, 3, 1, 3, 1, 1, 1, 1, 1, 1, 1, 2, 2, 1, 2, 2,...
## ..@ label : chr "Num. Conocidos: Gerente o director de gran empresa"
## ..@ format.stata: chr "%12.0g"
## ..@ labels : Named num [1:9] -999 -888 1 2 3 4 5 6 7
## .. ..- attr(*, "names")= chr [1:9] "No Responde (no leer)" "No Sabe (no leer)" "Ninguno" "Uno" ...
## $ c01 : dbl+lbl [1:2983] 1, 1, 1, 1, 2, 1, 3, 3, 3, 1, 4, 3, 1, 1, 1, 2, 3, 3,...
## ..@ label : chr "Satisfaccion con la democracia en Chile"
## ..@ format.stata: chr "%12.0g"
## ..@ labels : Named num [1:7] -999 -888 1 2 3 4 5
## .. ..- attr(*, "names")= chr [1:7] "No Responde (no leer)" "No Sabe (no leer)" "Nada satisfecho" "Poco satisfecho" ...
## NULLAhora bien, la utilidad de tener una buena base de datos, con etiquetas, variables y categorías bien estructuradas, es que facilita el análisis y el trabajo con la base de dato de modo tal que los gráficos de los programas reconocen esta estructura. Además, tener la base de datos bien estructurada y con información permite identificar las variables de modo correcto, disminuyendo los posibles errores. A continuación, podemos ver la misma base de datos de la cual evaluamos a estructura, a partir de un código que genera un libro de códigos automáticos.
| ID | Name | Type | Label | Values | Value Labels |
|---|---|---|---|---|---|
| 1 | t01 | numeric | Cuanto confia usted en sus vecinos |
-999 -888 1 2 3 4 5 |
No Responde (no leer) No Sabe (no leer) Muy poco Poco Algo Bastante Mucho |
| 2 | r01_01 | numeric | Num. Conocidos: Gerente o director de gran empresa |
-999 -888 1 2 3 4 5 6 7 |
No Responde (no leer) No Sabe (no leer) Ninguno Uno Entre 2 y 4 Entre 5 y 7 Entre 8 y 10 Entre 11 y 15 16 o mas |
| 3 | c01 | numeric | Satisfaccion con la democracia en Chile |
-999 -888 1 2 3 4 5 |
No Responde (no leer) No Sabe (no leer) Nada satisfecho Poco satisfecho Algo satisfecho Bastante satisfecho Muy satisfecho |
Por el contrario, si tenemos una “base de datos” que es creada en excel como en la imagen posterior, sin estructurar el contenido sobre las etiquetas de las variables ni las etiquetas de los valores y utilizamos el mismo código para la creación un libro de códigos, este no será muy informativo. Esto dificultaría el trabajo con esta base de datos, haciendo necesario agregar las etiquetas manualmente facilitando errores de codificación.
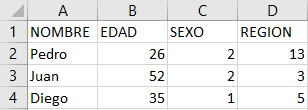
| ID | Name | Label | Values | Value Labels |
|---|---|---|---|---|
| 1 | NOMBRE | <output omitted> | ||
| 2 | EDAD | range: 26-52 | ||
| 3 | SEXO | range: 1-2 | ||
| 4 | REGION | range: 3-13 | ||
Además de que las bases de datos se encuentren bien estructuradas es importante que las etiquetas de las variables y las categorías se encuentren codificadas en “UTF-8” para que las letras puedan ser interpretadas por algunos softwares. Además de tener este tipo de codificación, es necesario que las bases de datos no posean tildes ni signos especiales (p. ej ¿ " , ;), preferentemente solo dígitos alfanuméricos. De lo contrario se generan problemas de codificación que resultan en errores visibles como los que se presentan a continuación.
EncuestaCEPjul <- read_sav("EncuestaCEPjul.sav")
Encuesta_CEP <- select(EncuestaCEPjul, SV1, MB_P2, ELE_7_1)
sjPlot::view_df(Encuesta_CEP, encoding = "UTF-8")| ID | Name | Label | Values | Value Labels |
|---|---|---|---|---|
| 1 | SV1 |
Considerando todas las cosas, ¿cuán satisfecho está usted con su vida en este momento? |
1 10 88 99 |
Totalmente insatisfecho Totalmente satisfecho No sabe No contesta |
| 2 | MB_P2 |
¿Cómo calificarÃa Ud. la actual situación económica del paÃs? |
1 2 3 4 5 8 9 |
Muy mala Mala Ni buena ni mala Buena Muy buena No sabe No contesta |
| 3 | ELE_7_1 |
Para cada actividad que le nombraré indique si Ud. la realiza frecuentemente, a veces, o nunca. Mira programas polÃticos en televisión |
1 2 3 8 9 |
Frecuentemente A veces Nunca No sabe No contesta |
Junto de la importancia de la estructura de la base de datos, las etiquetas y la codificación es necesario revisar algunos otros puntos sobre una base de datos sociales antes de subirla, como lo pueden ser el tema de la documentación necesaria o el tema de la privacidad, a continuación, haremos una revisión de los distintos temas que son importantes para la publicación de una base de datos.
El proceso de preparación por el cual se llega a una base bien etiquetada, bien codificad y anonima se denomina curatoria. Por ello, la curatoria de datos es fundamental antes de compartir una base de datos para que todos los usuarios de ella puedan comprender adecuadamente su contenido y trabajar con la menor cantidad de complicaciones.